Model Overview
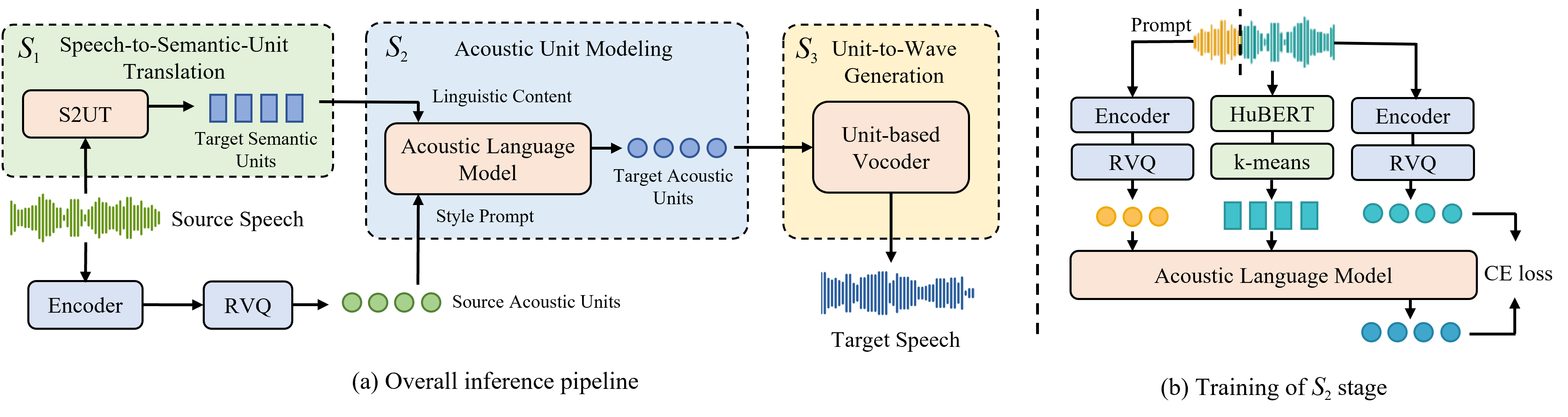
Our method comprises three consecutive stages, utilizing two distinct types of discrete units: 1) speech-to-semantic-unit translation stage S1, which converts source audio into semantic units of the translated speech; 2) acoustic unit modeling stage S2, generating target acoustic units conditioned on the semantic output from the preceding stage and the acoustic units of the source speech as style prompt; 3) unit-to-wave generation stage S3, producing translated speech that maintains consistent style with the source.
The training procedure of S2 adopts a self-supervised training paradigm, where the first three seconds of each audio sample is truncated as prompt, and the acoustic language model is trained to predict the acoustic units of the remaining part conditioned on its semantic units and the prompt acoustic units with cross-entropy loss. This in-context learning approach enables the model to grasp the correspondence in acoustic characteristics between the two parts and acquire style transfer ability. During inference, we use semantic tokens from the previous stage and acoustic units of source speech as the style prompt to realize cross-lingual style transfer.